I have added a new page to the site, called “Findings and honors“.
This page list all the Information Security vulnerabilities and other issues that I have discovered in my long career, including the last occasion – being added to the Israeli government “Hall of fame” for security researches who reported exposures in the Israel digital infrastructure.
I hope to extend this list in years to come… 😉
Category Archives: What have I discovered?
How I found an open SSH access on an Israeli government’s gov.il DNS server
I have much criticism about the Israeli government information security status and activity. Lots of PR and marketing for being a “Cyber Nation” but it is true mostly for the selling of knowledge, services and products. Not so much doing the “dirty work” of protecting the Israeli Internet facing IT, including the one of the Israel government itself.
So, I started this weekend to operate a mini-project of checking the quality of HTTPS sites of the gov.il sub-domains. I publish the results in a public spreadsheet, accessible as read-only (viewing, downloading and printing is allowed anonymously) from Google – https://docs.google.com/spreadsheets/d/1Fez2A1FwqesWRuc2DowpdG20okh-KDbYfO5qnl8nZ-U/edit?usp=sharing
While running these checks I found something alarming:
One of gov.il’s DNS servers, a server called dns3.gov.il, at 62.219.20.20 – replied at port 22 TCP, i.e. SSH, a service used to manage mostly Unix/Linux servers. Yes, open, allowing me try to login…
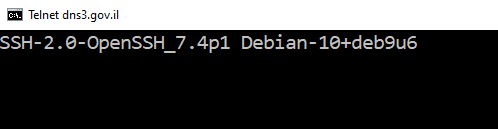
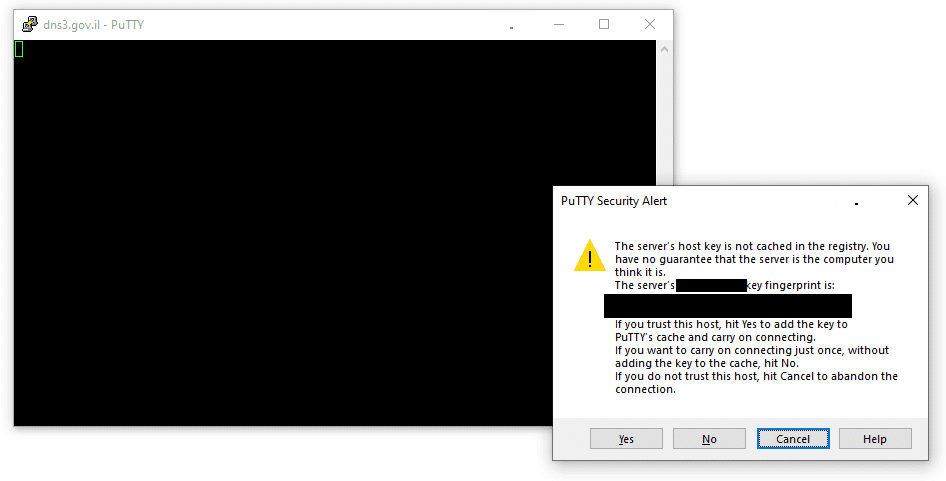
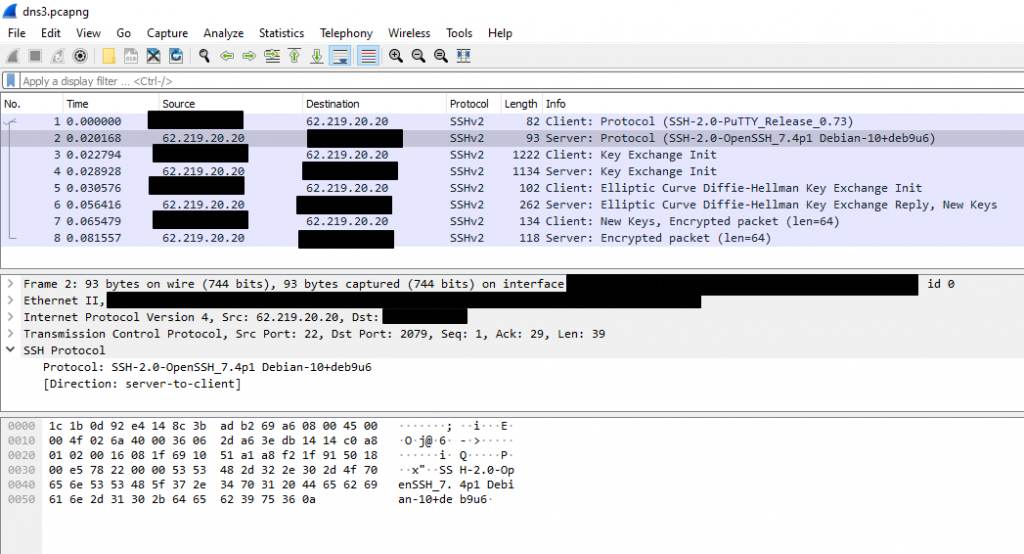
As I found it, in the afternoon of Friday, 31-Jan-20, I sent this finding at 16:28 to the Israeli national CERT and after ten minutes I also managed to correspond with someone I am in contact with, who was senior in government’s information security department, and he forwarded this issue to another security senior in the government’s IT, and he passed the details on to those who can fix this issue.
It took a few hours, but at the last check I did, around 21:30 that evening – access was blocked as this port has been closed, so it seemed to me that the issue had been addressed. Quite fast for almost Friday evening (the beginning of Shabbat in Israel).
Another point was that the SSH server identification was SSH-2.0-OpenSSH_7.4p1 Debian-10 + deb9u6, which means that the OpenSSH version is 7.4p1 that was released in December 2016, and since then several versions and a few security fixes for various security issues were released for OpenSSH, which are probably missing now from server. I hope they will update what is needed as soon as possible.
OpenSSH release notes
https://www.openssh.com/releasenotes.html
OpenSSH vulnerabilities
https://www.cvedetails.com/version-list/97/585/1/Openbsd-Openssh.html
Bug Bounty – when love is gone + Facebook privacy concern
One of the things I do not like for a long time, beyond the specific case described below, whose purpose was only to check the issue with the company, because it is clear to me that this is not a real vulnerability, but in my opinion only an unnecessary disclosure of private information to the client side – is that the Bug Bounty programs Kill the simple, largely innocent relationship between the reporter and report recipients.
Many times you just want to report relatively simple things, not terribly dangerous, not RCE, not SQLi, but defense is built from many layers and every closure helps protect, but “when money comes in – love is gone”, if I can describe it using an allegory.
Often times, especially in bug bounty outsourcing companies, such as HackerOne, they immediately close the report and even give you a “negative score” (which means you sent them nonsense and you are wasting their time) if you haven’t reached the reporting threshold that has a monetary reward. In my opinion, this approach is anti-information security and will only keep people from reporting to them, thus they are damaging their information security, because of their attitude.
The case below is with Facebook, which I believe discloses personal information to the client side without justification, or at least without a justification that is clear to me.
I understand and generally agree with their answer, but my security approach is to minimize exposure as much as possible, and I do not see in this case a justification for this exposure.
I wrote to them:
Title – Private user data from Facebook to Instagram
Vuln Type – Identification / Deanonymization
Product Area – Web
Description/Impact:
Hello,
I was wondering why when I try to login to Instagram, the site already knows my user name and suggest me login using it, so I investigated about it using Fiddler (I have matching saved Fiddler sessions).
The bottom line for this case is that in a reply to a POST method request to https://www.instagram.com/accounts/fb_profile/?hl=en, the client side gets a JSON plain text data (over HTTPS) with the following details, some originated from the already-Facebook-authenticated-client:
1. Instagram ID (assumed, the field is called “id”)
2. name – full name (first and family)
3. mobile_phone – full account mobile phone, with the international prefix, even if the relevant Instagram account has not set any mobile phone data at his/her Instagram account. Hence I guess it is a Facebook account data
4. email – the account’s FB email address, even if the FB account email address is different from the one at Instagram
5. username – the Instagram user name value, the one displayed to the user on the web page
I read the Instagram privacy policy and I see you mention that you can and will share user data between Facebook products and services, like between FB and Instagram, so in this front we are OK.
Also, the above process is done over HTTPS, so it *should* be secure during transit.
My claim is this:
It looks like most of the shared data is not needed for the login process but it is still sent to the client side, where it may be exposed or altered in various ways, like in companies that decrypt their internet traffic using their own cert at their IPS/UTM, hence allowing them to read the so called “secure” https data; or 3rd party browser plugins/extension at the client side; or any unknown other client side vulner or malware.
I guess that if you will only send the textual user name it will be enough – as it will be displayed for the user on the auto-login button and you will take care of the rest “behind the curtain”, with only minimal user data.
And if you do need, for some reason, to send all the above data to the client side – at least encrypt it, don’t send it as plain text.
Repro Steps
1. Use the latest chrome with a proxy extension, I like “Proxy SwitchyOmega” https://chrome.google.com/webstore/detail/proxy-switchyomega/padekgcemlokbadohgkifijomclgjgif?hl=en
2. Install the latest Fiddler and set it to decrypt HTTPS and click on the “Decode” toolbar button to auto-decode all incoming traffic, since the relevant response is GZIP encoded
3. Set the Chrome proxy plugin to direct its traffic to the Fiddler IP and port
4. Log into Facebook, verify Fiddler capture the traffic
5. Load the Instagram home page, https://www.instagram.com/?hl=en
6. Stop the Chrome extension from sending data to Fiddler (set it to “Direct”)
7. At Fiddler search for your phone number or just find the URL line of https://www.instagram.com/accounts/fb_profile/?hl=en
8. Review this line’s response pane in either RAW mode or JSON mode and you will see the above mentioned account details
Thanks.
Eitan Caspi
Israel
They replied:
Hi Eitan,
This is intentional behaviour in our product. If someone is browsing under the presence of UTM devices / malicious extensions / malware then their threat model is already compromised (eg. traffic passing through UTM can also include password / cookies of the user).
As such, we do not consider it a security vulnerability, but we do have controls in place to monitor and mitigate abuse.
